


Last week I wrapped up another Databricks Annual Summit in San Francisco. The summit is a useful read on where the data and AI market is heading, and this year the message was clear and consistent.
A week earlier, Snowflake had argued that enterprise AI gets real when you ground agents in governed data. Databricks made a related point from a different angle: the enterprise is being rebuilt around agents, and that forces the data layer underneath them to merge the operational, analytical, and real-time systems that have always been kept apart.
Databricks shared that 30,000 people attended in person, with a total of 100,000+ attendees overall across 150+ countries. Here are my takeaways, on what Databricks announced and on what the event felt like as an attendee and sponsor.
1. Key announcements by Databricks?
a) Genie One: An agentic coworker
Databricks has reframed Genie from a conversational-analytics feature into Genie One, a "data-smart agentic coworker". The interesting part is Genie Ontology, a context layer that continuously learns the business from Databricks plus 50+ connected apps (Google Drive, Jira, Slack, Confluence, SharePoint, and more). Databricks introduced Genie Agents, Genie App Builder, Genie Code, and Genie ZeroOps, a background agent that monitors and proposes fixes for pipelines, jobs, tables, and models.
b) LTAP: OLTP and OLAP in one architecture
The most architecturally interesting announcement was LTAP (Lake Transactional/Analytical Processing), which unifies transactions, analytics, and streaming on a single copy of data in the lake, no ETL, no replicas, no hidden CDC pipelines.
c) Lakehouse//RT: Real-time analytics on the lakehouse:
Lakehouse//RT, powered by a new compute engine called Reyden, brings millisecond query latency to tens of thousands of concurrent users and agents directly on governed Delta and Iceberg tables with no separate serving layer.. Note: Revefi’s RADEN, an autonomous AI Agent, has been used by F500 Enterprises to solve more complex use cases for Databricks, Snowflake and Google BigQuery since September 2024.
d) CustomerLake: Databricks enters marketing
Databricks launched CustomerLake, an agentic Customer Data Platform(CDP) built natively on the lakehouse and governed by Unity Catalog. Early customers include HP, Circle K, AB InBev, and Getnet by Santander.
e)Security Lakehouse
Databricks announced its intent to acquire Panther, an AI SOC platform, to accelerate its Lakewatch security-lakehouse vision against legacy SIEM.
2. My experience attending the sessions
I attended the keynotes on both days and a few breakout sessions. The keynotes focused on Databricks as a platform for ML, Analytical, Transactional, AI and Security workloads. The breakout sessions were informative and many of them were Databricks Accelerator projects and do-it-yourself projects.
3. Meeting data practitioners
The hallway and booth conversations were quite valuable during the event. Three things came up repeatedly, and they line up with what we see in our own data.
- Compute spend is the headline worry. As more workloads move to agents that run in loops, DBU consumption climbs, and teams are being asked to justify the spend. Most leaders want a clearer line from cost to value before they scale further.
- Agents are in pilots, not production. Almost everyone is testing agents; far fewer have them running against production data.
- Databricks is getting more complex to use and operate.
4. The Revefi experience as a sponsor
Sponsoring the summit gave me a different view of the event. Booth traffic was steady, and the conversations were the ones we hoped for, because the problems we focus on, runaway data spend, silent quality issues, and performance bottlenecks, are already on the agenda for most data leaders.

Watching the Revefi AI DBA for Databricks flag cost anomalies and data quality issues in minutes resonated, especially against a summit built on the assumption that agents already have trusted, well-governed data underneath them. A common reaction: this is the operating layer the main stage takes for granted.
We closed deals, advanced opportunities and met 75+data leaders, including CDOs and CDAOs, VPs of Data and Analytics, VPs of AI, and platform owners. The off-the-record conversations covered how teams are budgeting for AI workloads, where FinOps and data observability meet, and how to earn enough trust in the data before handing it to an agent.
How Revefi fits the Databricks ecosystem
If the takeaway from the summit is that the agentic enterprise runs on a single, governed, cost-controlled copy of data, then Revefi is the ROI foundation. Databricks announced the agents, the context layer, and the real-time engine on top.
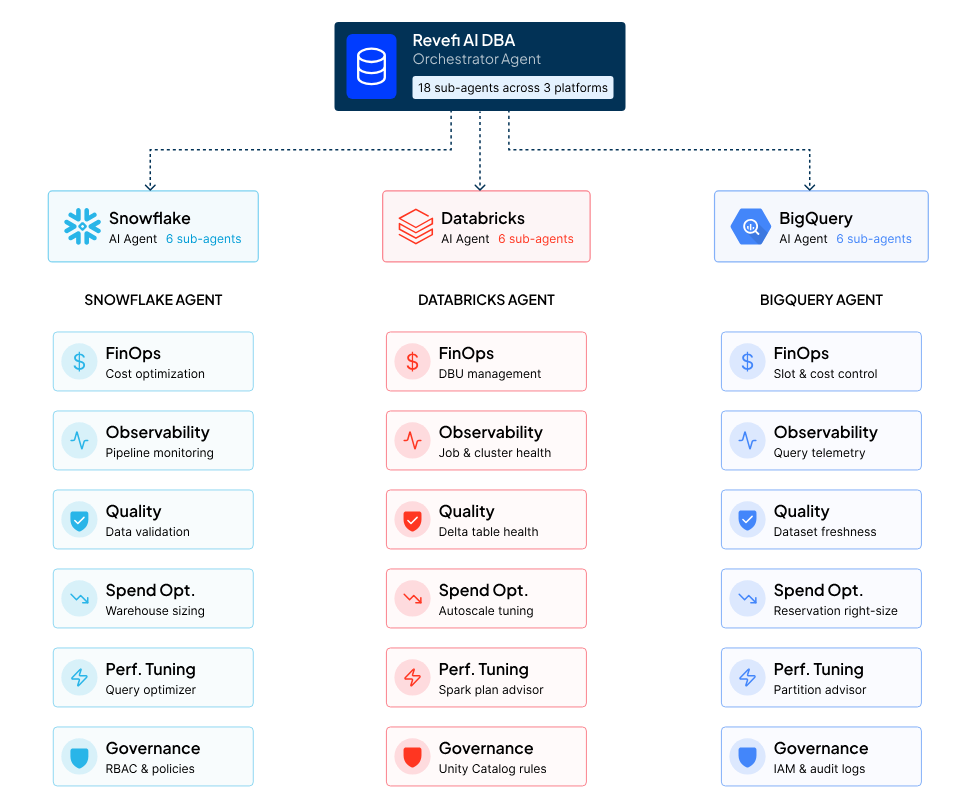
Revefi is the 24x7 AI DBA, continuously and autonomously monitoring cost, quality, performance, and operations so the data feeding those agents stays trustworthy and the consumption powering them stays predictable. The more the market leans into agents, the more that foundation matters.
Final thoughts
Databricks Summit 2026 made a clear case that the advantage in enterprise AI will come less from the model and more from the data and Agents. I came away with a better sense of where the platform is going, and with confirmation that the practitioners doing this work already understand that the unglamorous parts, data trust and cost control, are what make the agentic future workable.


